Appearance
Embedding模型实操
1 Embedding模型
1.1 什么是Embedding模型
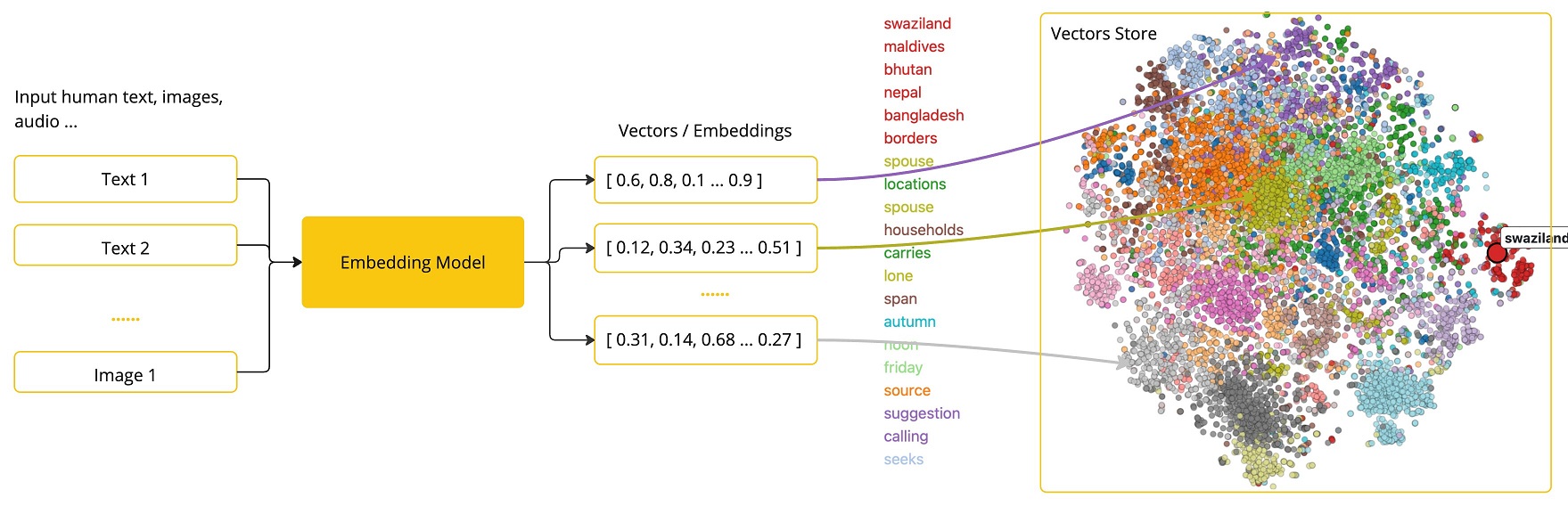
Embedding模型是指将高维度的数据(例如文字、图片、视频)映射到低维度空间的过程。简单来说,embedding向量就是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。
Embeddings的学习通常基于无监督或弱监督的方法。对于自然语言处理任务,常用的Embeddings方法包括Word2Vec、GloVe和FastTex。这些方法可以从大规模的文本语料库中学习单词的分布式表示。对于计算机视觉任务,常用的Embeddings方法包括卷积神经网络(CNN)和循环神经网络(RNN)等。
通俗易懂的描述: 嵌入就相当于给文本穿上了“数字化”的外衣 ,目的是让机器更好的理解和处理。
发展:由静态的Word Embedding(如Word2Vec、GloVe和FastText) -> 动态预训练模型 (如ELMo、BERT、GPT、GPT-2、GPT-3、ALBERT、XLNet等)。大型语言模型可以生成上下文相关的 embedding 表示,可以更好地捕捉单词的语义和上下文信息。
1.2 向量空间(Vector Space)
所有的数据都变成向量,这些向量组成一个庞大的矩阵,在这个世界里,每个词、句子、图片、用户…都被表示成一个"点”(即向量),大家都有自己的”“坐标”。
我们可以通过“距离“和“方向”来理解它们的关系。
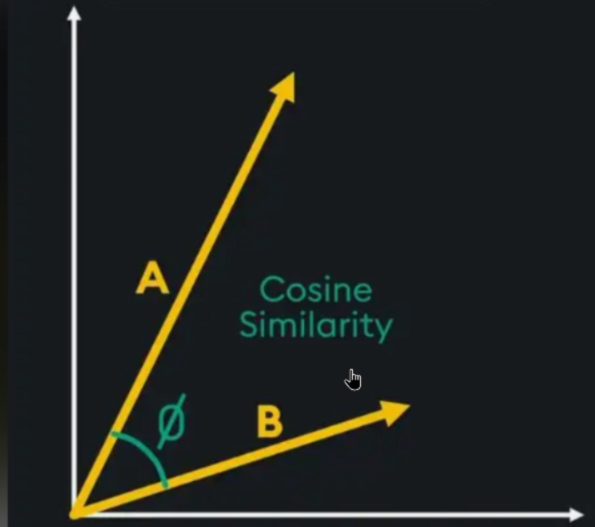
Embedding 向量放在向量空间里,有啥用?
距离表示相似度
- 向量之间越近:意义越相似
- 向量之间越远:意义越不同
比如:
- “苹果” 和 “香蕉” 的向量夹角小(近) -> 都是水果
- “苹果” 和 “MacBook” 的向量略远 -> 一个是水果,一个是电子产品
1.3 使用场景
- Embeddings可以在各种机器学习任务中使用,包括分类、聚类、检索和推荐等。
- 在自然语言处理任务中,可以使用静态预训练的Embeddings模型,如Word2Vec、GloVe和FastText,来生成单词的向量表示。这些预训练的Embeddings模型通常在大规模的文本数据上进行训练,可以用于处理不同的自然语言处理任务,如情感分析、命名实体识别和机器翻译等。
- 在计算机视觉任务中,可以使用卷积神经网络(CNN)提取图像的特征向量,然后使用这些特征向量进行分类、检索和生成等任务。另外,通过将图像与文本进行联合训练,可以学习到图像和文本之间的语义关系,从而实现图像与文本的检索和生成等任务。
- 我们在做RGA开发时又会涉及到向量数据库,在创建向量数据库时又需要使用Embedding模型对文本进行向量化处理。在检索的时候,需要对用户输入进行向量化处理也需要用到。
1.4 解决问题
- 降维: 在高维度空间中,数据点之间可能存在很大的距离,使得样本稀疏,嵌入模型可以减少数据稀疏性。
- 捕捉语义信息: Embedding不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。语义相近的词在向量上也是相近的- 特征表示:原始数据的特征往往难以直接使用,通过嵌入模型可以将特征转换成更有意义的表示。
- 计算效率:在低维度空间中对数据进行处理和分析往往更加高效。
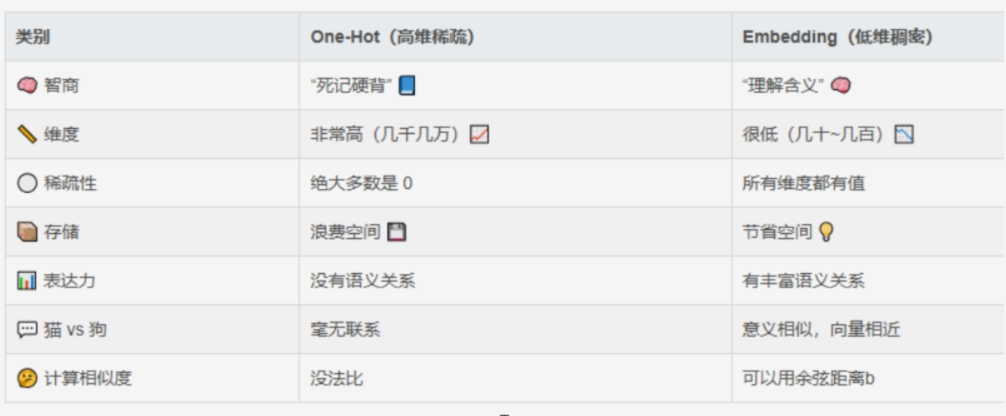
1.5 独热编码(One-Hot Encoding)
是一种将数据转换为二进制向量的技术。它的主要目的是将分类变量转换为机器学习算法能够处理的格式,从而避免数值关系的误判。
举例:词表中有 10,000 个词,每个词都用一个只有一个 1,其它全是0 的向量来表示。

2 LangChain的文本嵌入模型(Embedding)
嵌入模型创建文本片段的向量表示,您可以将向量视为一个数字数组,它捕捉了文本的语义含义。 通过这种方式表示文本,您可以执行数学运算,从而进行诸如搜索其他在意义上最相似的文本等操作。
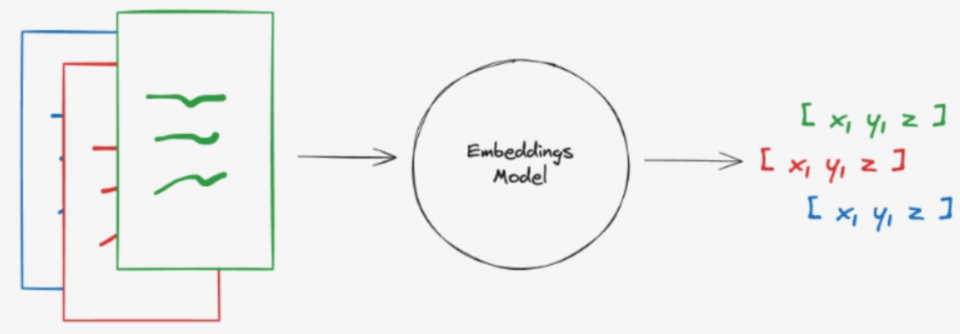
Embeddings 类是一个用于与文本嵌入模型接口的类。有很多嵌入大模型供应商(0penAI、Hugging Face,BGE 等) - 这个类旨在为它们提供一个标准接口。
LangChain 中的基础 Embeddings 类提供了两个方法:一个用于嵌入文档,一个用于嵌入查询。
- 前者,.embed_documents,接受多个文本作为输入
- 后者,.embed_query,接受单个文本。
- 将这两个方法分开是因为某些嵌入大模型供应商对文档(待搜索的内容)和查询(搜索查询本身)有不同的嵌入方法。
- .embed_query 将返回一个浮点数列表
- .embed_documents 返回一个浮点数列表的列表。
3 在线调用向量模型
3.1 OpenAI调用
python
from openai import OpenAI
client = OpenAI(
api_key= '',
base_url=''
)
text = 'I like large language modeLs.'
resp = client.embeddings.create(
model='text-embedding-3-large',
dimensions=256,
input=text
)
print(resp.data[0].embedding)
print(len(resp.data[0].embedding))3.2 LangChain调用
bash
pip install langchain-openaipython
from langchain_openai import OpenAIEmbeddings
openai_embedding = OpenAIEmbeddings(
api_key='',
base_url='',
model='text-embedding-3-large',
dimensions=256,
)
resp = openai_embedding.embed_documents(
[
'I like large language modeLs.',
'今天天气不错'
]
)
print(resp[0])
print(len(resp[0]))4 私有化部署向量模型
Huggingface 上的 BGE 模型是最好的开源嵌入模型之一。 BGE 模型由北京人工智能研究院(BAAI)创建。 是一家从事 AI 研发的私营非营利组织。
首先,配置HuggingFace镜像站: https://hf-mirror.com/
其次,为了部署Embedding模型,我们需要引入对应的工具库,目前主要有几类:
Sentence-Transformers: Sentence-Transformers库是基于Huggingface的Transformers库构建的,它专门设计用于生成句子级别的嵌入。它引入了一些特定的模型和池化技术,使得生成的嵌入能够更好地捕捉句子的语义信息,Sentence-Transformers库特别适合于需要计算句子相似度、进行语义搜索和挖掘同义词等任务。
HuggingFace Transformers: HuggingFace的Transfomers,库是一个广泛使用的NLP库,它提供了多种预训练模型,如BERT、GPT-2、ROBERTa等,这些模2型可以应用于各种NLP任务,如文本分类、命名实体识别、问答系统等。Transformers库支持多种编程语言,并且支持模型的微调和自定义模型的创建。虽然Transformers库的功能强大,但它主要关注于模型的使用,而不是直接提供句子级别的嵌入。
Langchain集成的HuggingFaceBgeEmbeddings。与3一样。
FlagEmbedding:这是一个相对较新的库,其核心在于能够将任意文本映射到低维稠密向量空间,以便于后续的检索、分类、聚类或语义匹配等任务。FlagEmbedding的一大特色是它可以支持为大模型调用外部知识,这意味着它不仅可以处理纯文本数据,还能整合其他类型的信息源,如知识图谱等,以提供更丰富的语义表示。
总的来说,FlagEmbedding强调的是稠密向量的生成和外部知识的融合: HuggingFace Transformers提供了一个广泛的预训练模型集合,适用于多种NLP任务;而Sentence-Transformers则专注于生成高质量的句子嵌入,适合那些需要深入理解句子语义的应用场景。
4.1 下载BGE
代码在modelscope里面
- 第一次运行,会自动下载模型(去huggingface上下载),下载到hf默认的缓存目录。
- 第一次下载的目录 C:\Users\XXX.cache\huggingface\hub
- 缓存目录-可以通过修改环境变量:HF_HOME=指定目录
python
# from langchain.embeddings import HuggingFaceBgeEmbeddings
# from langchain_community.embeddings import HuggingFaceBgeEmbeddings
# 第一种
# 第一次运行,会自动下载模型(去huggingface上下载),下载到hf默认的缓存目录。
# 第一次下载的目录 C:\Users\XXX\.cache\huggingface\hub
# 缓存目录-可以通过修改环境变量:HF_HOME=指定目录
# pip install langchain-community
# pip install sentence-transformers
# 第二种
# pip install langchain-huggingface
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
# 模型名称
model_name = "BAAI/bge-small-zh-v1.5"
# 使用的设备为cuda
model_kwargs = {'device': 'cpu'}
# set True to compute cosine similarity
encode_kwargs = {'normalize_embeddings': True}
# bge_hf_embedding = HuggingFaceBgeEmbeddings(
# model_name=model_name,
# model_kwargs=model_kwargs,
# encode_kwargs=encode_kwargs,
# )
bge_hf_embedding = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
resp = bge_hf_embedding.embed_documents(
[
'I like large language modeLs.',
'今天天气不错'
]
)
print(resp[0])
print(len(resp[0]))4.2 下载Qwen3
python
# 需要安装 pip install sentence-transformers
# 安装 sentence-transformers 会自动安装 transformers
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
qwen3_embedding = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
resp = qwen3_embedding.encode(
[
'I like large language modeLs.',
'今天天气不错'
]
)
print(resp[0])
print(len(resp[0]))4.3 LangChain整合Qwen3 Embedding
python
from langchain_core.embeddings import Embeddings
from sentence_transformers import SentenceTransformer
# qwen3 整合 langchain
class CustomQwen3Embedding(Embeddings):
"""自定义一个qwen3的Embedding和Langchain整合的类"""
def __init__(self, model_name):
self.qwen3_embedding = SentenceTransformer(model_name)
def embed_query(self, text: str) -> list[float]:
return self.embed_documents([text])[0]
def embed_documents(self, texts: list[str]) -> list[list[float]]:
return self.qwen3_embedding.encode(texts)
if __name__=='__main__':
qwen3_embedding = CustomQwen3Embedding("Qwen/Qwen3-Embedding-0.6B")
resp = qwen3_embedding.embed_documents(
[
'I like large language modeLs.',
'今天天气不错'
]
)
print(resp[0])
print(len(resp[0]))5 案例
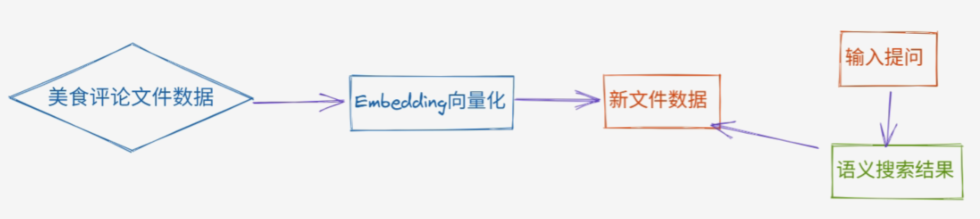

python
# 04-embedding1-美食评论案例
import ast
import numpy as np
import pandas as pd
from langchain_community.embeddings import HuggingFaceEmbeddings
# 模型名称
model_name = "BAAI/bge-small-en-v1.5"
# 使用的设备为cuda
model_kwargs = {'device': 'cpu'}
# set True to compute cosine similarity
encode_kwargs = {'normalize_embeddings': True}
bge_hf_embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
def text_2_embedding(text):
resp = bge_hf_embedding.embed_documents([text])
return resp[0]
def embedding_2_file(source_file, output_file):
"""读取原始的美食评论数据,通过调用Embedding模型,得到向量,并保持到新文件中"""
# 步骤 1:准备数据,并读取
df = pd.read_csv(source_file, index_col=0) # index_col 排除第一列
df = df[['Time', 'ProductId', 'UserId', 'Score', 'Summary', 'Text']]
print(df.head(2))
# 步骤 2:清洗数据和合并数据
# 把评论的摘要和内容字段合并成一个字段(方便后续处理)
df['text_content'] = 'Summary: ' + df.Summary.str.strip() + '; Text: ' + df.Text.str.strip()
print(df.head(2))
# 步骤3: 向量化,存到一个新的文件中
df['embedding'] = df.text_content.apply(lambda x: text_2_embedding(x))
df.to_csv(output_file)
# 计算两个向量的余弦距离
def cosine_distance(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def search_text(input, embedding_file, top_n=3):
"""
根据用户输入的问题,进行语义检索,返回最相似的前top_n个结果
:param input:
:param embedding_file:
:param top_n:
:return:
"""
df_data = pd.read_csv(embedding_file)
# 把字符串变成向量中,保存到新的字段 (ast.literal_eval 字符串转向量的函数)
df_data['embedding_vector'] = df_data['embedding'].apply(ast.literal_eval)
input_vector = text_2_embedding(input)
df_data['similarity'] = df_data.embedding_vector.apply(lambda x: cosine_distance(x, input_vector))
res = (
# similarity 降序排列
df_data.sort_values('similarity', ascending=False)
.head(top_n)
.text_content.str.replace('Summary: ', '')
.str.replace('; Text: ', ';')
)
for r in res:
print(r)
print('-' * 30)
if __name__ == '__main__':
# embedding_2_file('../datas/fine_food_reviews_1k.csv', '../datas/output_embedding.csv')
search_text('delicious beans', '../datas/output_embedding.csv')