Appearance
1 服务器
1.1 算力租用
1.1.1 AutoDL
autoDL 选用4090或4090D卡
autoDL 如果需要暴露ip,需要进行隧道代理
- 帮助文档 》 搜索 》 隧道
- 地址:https://autodl.com/docs/ssh_proxy/
- 下载进行代理
- 帮助文档 》 搜索 》 隧道
开启学术加速
sh
source /etc/network_turbo- 取消学术加速
sh
unset http_proxy && unset https_proxy- 默认数据盘是 /root/autodl-tmp
1.1.2 算力云
后面来补
1.2 连接服务器
1.2.1 vscode连接
1.2.2 安装vscode
- 官网下载
1.2.3 安装插件 remote-ssh
- 安装插件
1.2.4 连接
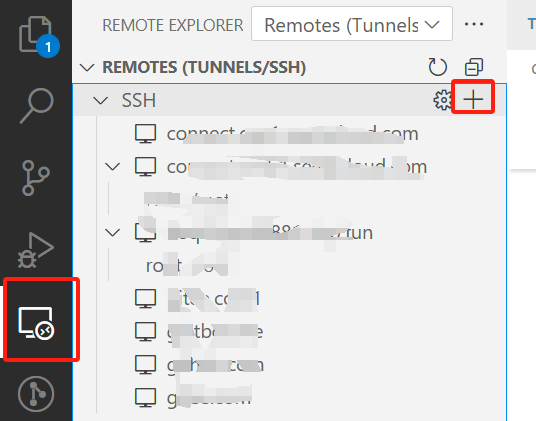
然后输入链接地址和密码即可
1.3 ModelScope 模型下载
1.3.1 安装包
python
pip install modelscope1.3.2 下载方式
1 命令下载
具体看官网
2 SDK下载
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B')1.3.3 下载Qwen/Qwen3-8B
在autodl-tmp/code路径下面新建download.py文件
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B', cache_dir='/root/autodl-tmp/models', revision='master')执行下载命令
python
python download.py1.3.4 下载 deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-0528-Qwen3-8B', cache_dir='/root/autodl-tmp/models', revision='master')3 Git下载
- 看官网
1.4 查看机器配置
1.4.1 查看机器原有配置
sh
nvidia-smi1.4.2 查看显存占用情况
sh
pip install nvitop
nvitop模型训练 》 显存占用90%为最佳,不能超过
2 私有化部署
2.1 vllm server命令部署模型
2.1.1 企业级别的部署-vllm
sh
# 安装vllm包
pip install vllm
# 更新vllm包
pip install upgrade vllm2.1.2 Qwen3的部署命令
bash
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen/Qwen3-8B \
--served-model-name qwen3-8b \
--max-model-len 8k \
--host 0.0.0.0 \
--port 6006 \
--dtype bfloat16 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes
# MOE架构才加下面的两个参数
# 开启ds的深度思考
--enable-reasoning \
# 指定深度思考的模式
--reasoning-parser deepseek_r1 \TIP
企业至少推理速度需要大于等于80个token/秒,低了就加算力
常规4090一张卡用8b的模型推理速度大概是50个token/秒
部署成功后,使用隧道代理,然后访问,会出现fastapi的接口文档就表示成功了
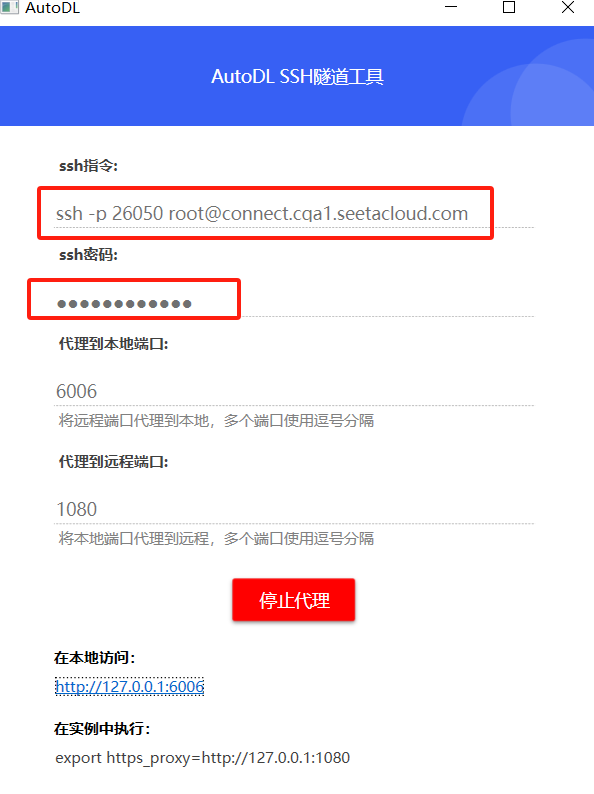
访问
sh
http://127.0.0.1:6006/docs2.1.3 DeepSeek-R1-0528-Qwen3-8B的部署命令
bash
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B \
--served-model-name ds-qwen3-8b \
--max-model-len 8k \
--host 0.0.0.0 \
--port 6006 \
--dtype bfloat16 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes2.2 API调用
2.2.1 安装openai库
sh
pip install langchain
pip install langchain-openai langchain-community2.2.2 OpenAI测试连接qwen3-8b
python
from openai import OpenAI
'''
测试连接vllm模型部署
'''
# base_url 必须正确 api_key 随意,私有化部署用不到
client = OpenAI(base_url='http://localhost:6006/v1', api_key='xxxx')
resp = client.chat.completions.create(
# 模型名称
model='qwen3-8b',
# 提示词
messages=[{'role':'user', 'content': '请介绍一下什么是深度学习?'}],
# 温度
temperature=0.8,
# 最大上下文长度
# max_tokens='8K',
# 大模型生成内容不重复
presence_penalty=1.5,
# qwen3特有的参数: enable_thinking 表示是否开启深度思考
extra_body={'chat_template_kwargs': {'enable_thinking': True}}
)
print(resp)
print(resp.choices[0].message.content)2.2.3 ChatOpenAI测试连接qwen3-8b
使用langchain来调用本地私有化,以后项目开发也是用这种方式
python
from langchain_openai import ChatOpenAI
# 调用本地的私有化大模型
llm = ChatOpenAI(
model='qwen3-8b',
temperature=0.8,
api_key='xxx',
base_url='http://localhost:6006/v1',
# qwen3特有的参数: enable_thinking 表示是否开启深度思考
extra_body={'chat_template_kwargs': {'enable_thinking: true'}}
)
# 设置提示词
message = [
('system', '你是一个智能助手'),
('human', '请介绍一下什么是深度学习?')
]
# 调用大模型
resp = llm.invoke(message)
print(resp)2.2.4 ChatOpenAI测试连接ds-qwen3-8b
只需要把模型名称换了接口
python
from langchain_openai import ChatOpenAI
# 调用本地的私有化大模型
llm = ChatOpenAI(
model='ds-qwen3-8b',
temperature=0.8,
api_key='xxx',
base_url='http://localhost:6006/v1',
# qwen3特有的参数: enable_thinking 表示是否开启深度思考
extra_body={'chat_template_kwargs': {'enable_thinking: true'}}
)
# 设置提示词
message = [
('system', '你是一个智能助手'),
('human', '请介绍一下什么是深度学习?')
]
# 调用大模型
resp = llm.invoke(message)
print(resp)