Appearance
机器学习三大任务类别
一、什么类型的问题适合使用机器学习的方法来处理呢?
- 有充足的训练数据
- 简单的编程无法做到
- 问题的可解决性
| 场景 | 描述 | |
|---|---|---|
| 分类 | 二分类 | 预测结果只有两个离散的值,比如“1/0”,“是/否” |
| 多分类 | 预测结果是多个离散的值,比如“A、B、C...” | |
| 回归 | 预测的结果是连续的值,如房价的预测,天气温度的预测等 | |
| 聚类 | 将相似的样本归类在一起,如用户画像等 | |
二、分类
1、定义
分类问题:教机器去学习给定的数据,然后将未知的数据分到不同类别中去。
通常包括一个“训练阶段”,用已知的数据来教机器如何进行分类,然后在“测试阶段”的时候,用这个机器来对新的未知数据进行分类。
- 二分类问题:判断一个事情的结果是“男 / 女”、“是 / 否”、“1/0”,这种问题它的结果只有两个互斥且全覆盖的值。
- 多分类问题:预测结果是三个或三个以上情况的。
2、案例1
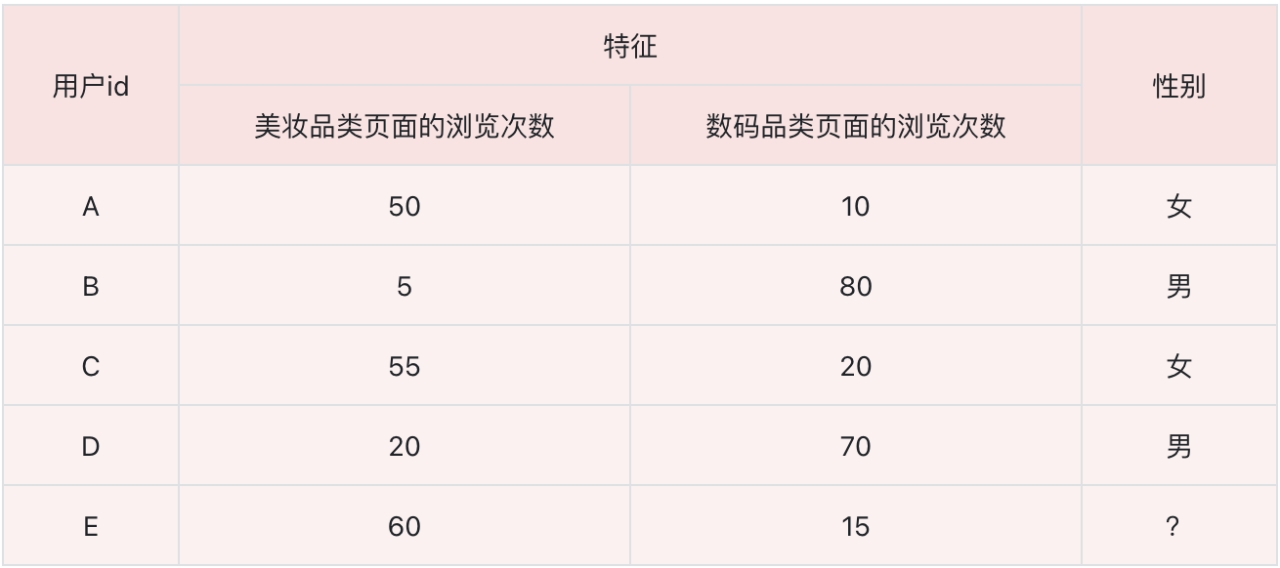
根据用户 A、B、 C、D 的性别数据,来预测商城其他用户的性别。
三、回归
1、定义
回归问题:预测的结果是连续值。
类比为方程: 给一些自变量 x 和因变量 y 的具体值,拟合成一个方程 y=f(x)。
2、案例1
判断当前某个商品的库存是否足够。
- 判断方式:预测未来该产品的销量,根据预测结果判断库存是否足够。
- 预测原理:通过观察数据发现,某个产品的被搜索次数越多,销量就越高。
一个产品销量的影响因素:
- 折扣的力度
- 用户的评价
- ......
这 n 个特征,总结到一个回归方程里:
销量 = a0 + a1 · 搜索次数 + a2 · 用户评价 + a3 · 折扣力度 + ...
3、案例2
一个房地产经纪人,通过一些房子的各种数据(面积、卧室数量、地理位置等)和实际的售价,就可以“训练”出一个模型。
当给出一个新房子的各种特点后,就可以预测这个房子的售价。
三、聚类
1、定义
- 聚类问题:根据“物以类聚”的原理,将我们给定的样本聚集成不同组的过程。
- 目的:尽可能使属于同一个组里的样本相似,而属于不同组的样本应该足够不相似。
与分类问题不同,进行聚类前并不知道将要划分成几个组,以及是什么样的组,训练数据没有结果,没有标签,完全依靠算法进行聚类。
2、案例1
用户画像:根据用户的年龄、购买频率、购买的商品类别、消费金额等等数据,将相似的用户进行聚类,分成几个不同的组。
假设一个电商平台,有以下几个客户的数据(只展示了三个特性):
分类结果
- 小组 1:客户 1 和客户 3(年轻,购买频率高,消费金额相对低)
- 小组 2:客户 2、客户 4 和客户 5(年龄偏大,购买频率低,消费金额相对较高或中等)
针对不同的用户进行不同的营销应用:
- 对于小组 1 的用户:推送更多低价、高频的商品。
- 对于小组 2 的用户:推送更多高价、高品质的商品。