Appearance
人工智能发展历史
- Al (Artificial Intelligence)人工智能 是一种使机器能够模拟人类智能的技术,通过机器学习、深度学习等算法,使得计算机具备学习、推理、自我修正和解决问题等功能。
- 包括了语言、原因、视觉、多模态(感知和决策)
发展历史图
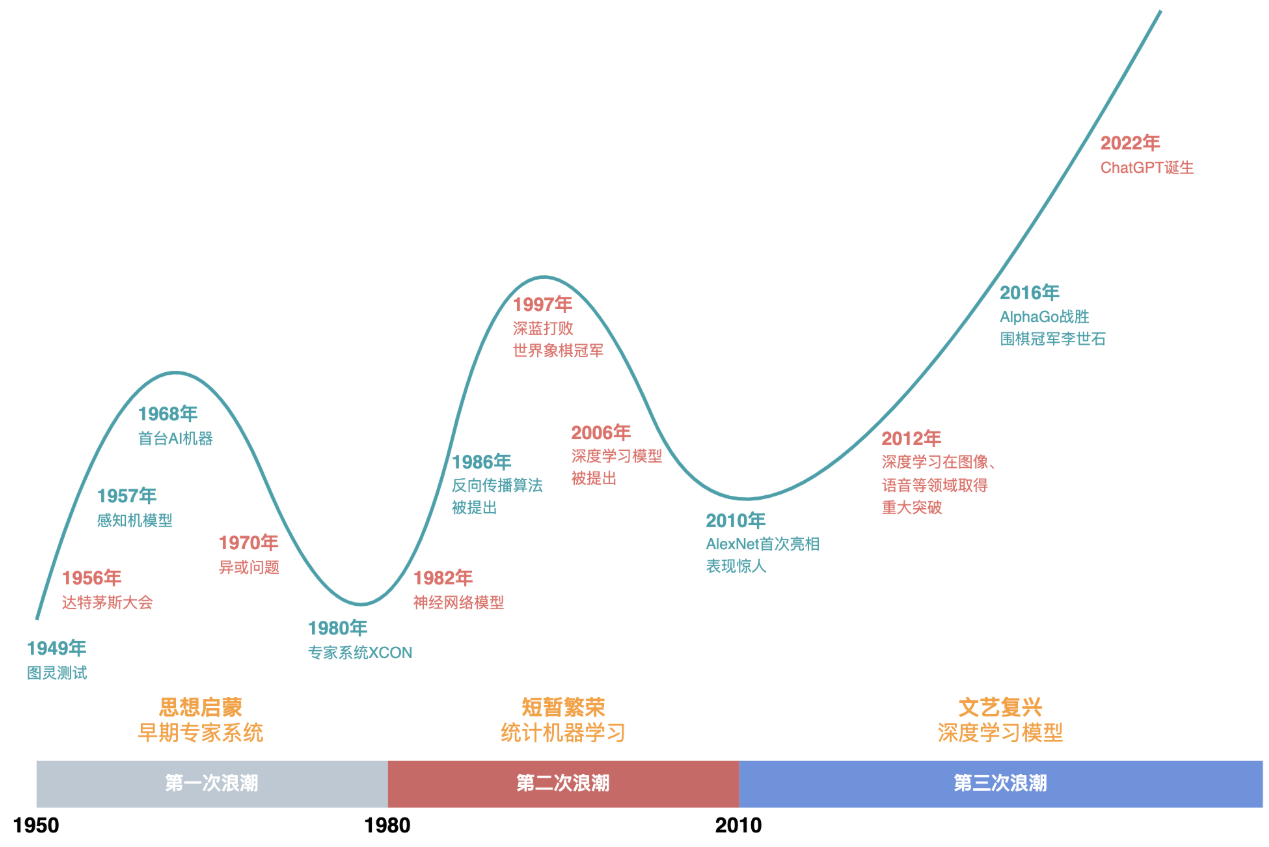
学习任一门知识都应该先从其历史开始,把握了历史,也就抓住了现在与未来。
一、人工神经网络
- 1943 年,由神经科学家 麦卡洛克(W.S.McCilloch) 和数学家皮兹(W.Pitts) 在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity)。建立了神经网络和数学模型,称为 MCP 模型。
- 所谓MCP模型,其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,也就诞生了所谓的“模拟大脑”。
- 该模型作为人工神经网络的起源,开创了人工神经网络的新时代,也奠定了神经网络模型的基础。
二、图灵测试
- 1950 年,阿兰·图灵(Alan Turing) 发表了一篇具有重要影响力的论文《计算机与智能》(Computing Machinery and Intelligence),提出了著名的图灵测试:“在测试人与被测试者(机器)不接触的情况下,经过多次问答后,测试人无法根据这些问题判断对方是人还是计算机,那么就可以认为这台机器是具有智能的”,简称“机器能否思考”的关键问题。在论文中,图灵提出了“模仿游戏”(即图灵测试)的概念,用来检测机器智能水平。
- 图灵测试引导了人工智能的多个研究方向。为了使计算机智能化,能够通过图灵测试,需要探寻如何用机器来模拟、延伸和扩展人类的智能,让机器会听、会看、会说、会思考、会行动、会决策,就像人类一样。因此,计算机必须具备理解语言、学习、记忆、推理、决策等能力。
三、概念提出-达特茅斯会议
1955 年,达特茅斯学院的麦卡锡教授(John McCarthy),首次提出了“人工智能”的概念,来概括神经网络、自然语言等“各类机器智能”技术。
1956 年,约翰·麦卡锡、马文·明斯基、香农共同推动召开了达特茅斯会议,也叫“人工智能夏季探讨会”(Summer Research Project on Artificial Intelligence)。会议的主题是:“让机器使用语言,形成抽象与概念,解决目前只有人类才能求解的问题,以及不断自我提升”。确定了人工智能的研究使命:“人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样”。
会议讨论的主要议题有以下 7 个方面:
- 自动计算机(自动指可编程)
- 如何为计算机编程,使其能够使用语言
- 神经网络
- 计算规模理论
- 自我改进(指机械学习)
- 抽象
- 随机性与创造性
达特茅斯研讨会进行了两个月,其中,纽厄尔和西蒙公布的程序“逻辑理论家”(Logic Theorist)引起参会者极大的兴趣,这个程序模拟人证明符号逻辑定理的思维活动,并成功证明了《数学原理》第 2 章 52 个定理中的 38 个定理,被认为是用计算机探讨人类智力活动的第一个真正成果,也是图灵关于机器可以具有智能这一论断的第一个实际证明。
此外,逻辑理论家开创了机器定理证明这一新的学科领域。
最终会议形成了一个共识:人工智能(AI)对人类具有很大的价值。
四、三大门派
达特茅斯会议上将 AI 定义为:尝试找到如何让机器使用语言、形成抽象和概念、解决现在人类还不能解决的问题、提升自己等等。对于当下的人工智能来说首要问题是让机器像人类一样能够表现出智能。
但是如何具体实现,则逐渐形成了三大主流门派。
- 符号学派(Symbolists): 又称为逻辑主义、心理学派或计算机学派。包含决策树,专家系统等技术。代表人物有约翰·麦卡锡、西蒙和纽厄尔、马文·明斯基等。各类决策树相关的算法,均受益于符号主义流派。
- 联结学派(Connectionists): 又称为仿生学派或生理学派,包含感知器,人工神经网络,深度学习等技术。代表人物有罗森·布莱特(Frank Rosenblatt)等。
- 行为学派(Actionist): 又称为进化主义或控制论学派,包含控制论、马尔科夫决策过程、强化学习等技术。代表人物有萨顿(Richard Sutton)等。
| 学派 | 研究 | 重视 |
|---|---|---|
| 符号学派 | 抽象思维 | 数学可解释性 |
| 联结学派 | 形象思维 | 仿人脑模型 |
| 行为学派 | 感知思维 | 应用和身体模拟 |
从共同性方面来说,算法、算力和数据是人工智能的三大核心要素, 无论哪个学派,这三者都是其创造价值和取得成功的必备条件。行为主义有一个显著不同点是它需要有一个智能的“载体”来感知环境,比如扫地机器人的身体,而符号主义和连接主义则不需要“载体”去感知周围环境。联结主义学派和行为主义学派都需要使用强化学习方法进行训练。三者之间的长处与短板都很明显,意味着彼此之间可以扬长补短,共同合作创造更强大的强大的人工智能。比如说将连接主义的“大脑”安装在行为主义的“身体”上,使机器人不但能够对环境做出本能的反应,还能够思考和推理。未来随着三大学派更加融合贯通,可共同为人工智能的实际应用发挥作用。
五、感知机的诞生
20 世纪 50 年代末,在 MCP 模型和海布学习规则的研究基础上,美国科学家罗森布拉特(Rosenblatt)发现了一种类似于人类学习过程的学习算法——感知机学习。
1958 年,Rosenblatt 正式提出了由两层神经元组成的神经网络,称之为“感知器(Perceptrons)”。
感知器本质上是一种线性模型,可以对输入的训练集数据进行二分类,且能够在训练集中自动更新权值。
1962 年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
感知器的提出吸引了大量科学家对人工神经网络研究的兴趣,对神经网络的发展具有里程碑式的意义。
感知机的提出带来了神经网络的繁荣,同样它的缺陷也让神经网络陷入低谷。
六、第一次寒冬
1969 年,美国数学家及人工智能先驱马文·明斯基( Marvin Minsky)在其著作中证明了感知器本质上是一种线性模型(linear model),只能处理线性分类问题,就连最简单的 XOR(异或)问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了将近 20 年的停滞。
客观上,感知机确实存在不小的问题。我们知道,感知机本身就是一条直线,它只能对线性可分的样本进行处理。对线性不可分的数据,感知机没法终止,并不是感知机算法找不到这条直线,而是这样的直线根本就不存在,感知机的弱点并不在其基本思想,而在于其简单的网络结构。
明斯基和帕普特用最简单却又明显不可分的异或问题给了感知机几乎致命的打击。主观上,有可能是明斯基和帕普特对罗森布拉特所取得的关注和追捧带有一些明显的负面情绪。他们认为,罗森布拉特的论文没有多少科学价值。
由于这个致命的缺陷以及没有及时推广感知器到多层神经网络中,任何其他线性分类模型(例如逻辑回归分类器)的日子都不好过,但是研究人员对感知机的期望更高,有些人感到失望,他们完全放弃了神经网络,转而支持更高层次的问题,例如逻辑、问题求解和搜索。
从 1974 年开始,人工智能的研究进入了第一个漫长的冬季(AI Winter)。明斯基对感知器的批评导致了人们对神经网络研究停滞了将近 20 年。当然,这也一定程度上要归咎于 AI 研究者们低估了 AI 课题的研究难度,做出各种不切实际的承诺,而且当时的模型和硬件计算能力的限制,也使得这些承诺完全无法按预期实现。
七、短暂的繁荣
1969 年马文·明斯基获得了图灵奖,宣布了“符号学派”派胜利后不久,AI 就迎来了第一次寒冬。或者说,计算力的匮乏导致了第一次 AI 寒冬,帮助“符号学派”实现逆袭。
到 1980 年代初,符号主义 AI 的研究人员带来了鼎盛时期,他们因特定学科(如法律或医学)知识的专家系统而获得资助。投资者希望这些系统能很快找到商业应用。
八、第二次寒冬
然而好景不长,星星之火未能燎原。不久之后,人们发现专家系统更新迭代和维护成本同样非常高,同时数据缺乏与计算性能的问题也并没有得到根本性的解决。在 1984 年的年度 AAAI(美国人工智能协会是人工智能领域的主要学术组织之一。该协会主办的年会 AAAI 是人工智能重要的学术会议之一)。会议上,人工智能专家罗杰·单克(Roger Schank)和马文·明斯基警告“AI 之冬”即将到来。预测 AI 泡沫破灭,投资资金也将如 1970 年代中期那样减少。
在他们发出警告后 3 年,确实发生了 AI 泡沫的破灭。苹果和 IBM 推出了比人工智能计算机更强大的通用计算机,随着计算机硬件性能的提升,更多人倾向于选择成本低廉的个人电脑而非昂贵的专家系统。
九、神经网络的重生
- 1982 年,物理学家 John Hopfield 向美国科学院提交了关于神经网络的报告,其主要内容是,建议收集和重视以前对神经网络所做的许多研究工作,证明一种新型的神经网络(现被称为“Hopfield 网络”)能够用一种全新的方式学习和处理信息,并指出了各种模型的实用性。随后,引起许多学者研究“Hopfield 网络”的热潮,对它作改进、提高、补充、变形等,大大推动了神经网络的发展。
十、AI 的文艺复兴
随着计算机技术的突飞猛进的发展,特别是互利网的诞生,加速了人工智能的创新研究,促使人工智能技术进一步走向实用化,人工智能相关的各个领域都取得长足进步。
在 2000 年代初,由于专家系统的项目都需要编码太多的显式规则,这降低了效率并增加了成本,人工智能研究的重心从基于知识系统转向了机器学习方向。人工智能终于开启了属于它的文艺复兴时代。
十一、深度学习
深度学习是机器学习的一个分支,它通过一个有着很多层处理单元的深层网络对数据中的高级抽象进行建模。
2006 年,杰弗里·辛顿(Geoffrey Hinton)以及他的学生鲁斯兰·萨拉赫丁诺夫(Ruslan Salakhutdinov)正式提出了深度学习的概念(Deeping Learning),开启了深度学习在学术界和工业界的浪潮。2006 年也被称为深度学习元年,杰弗里·辛顿(Geoffrey Hinton)也因此被称为深度学习之父。
2015 年,为纪念人工智能概念提出 60 周年,深度学习三巨头 LeCun、Bengio 和 Hinton(他们于 2018 年共同获得了图灵奖)推出了深度学习的联合综述《Deep learning》。
深度学习三巨头

- Geoffrey Hinton: 计算机学家、心理学家,被称为“神经网络之父”、“深度学习鼻祖”。现任加拿大多伦多大学教授,谷歌大脑首席科学家。他研究了使用神经网络进行机器学习、记忆、感知和符号处理的方法,并在这些领域发表了超过 200 篇论文。他是将(Backpropagation)反向传播算法引入多层神经网络训练的学者之一,他还联合发明了波尔兹曼机(Boltzmann machine)。他对于神经网络的其它贡献包括:分散表示(distributed representation)、时延神经网络、专家混合系统(mixtures of experts)、亥姆霍兹机(Helmholtz machines)等。
- Yann LeCun: 中文名“杨立昆”,计算机科学家,被誉为“卷积网络之父”,为卷积神经网络(CNN,Convolutional Neural Networks)和图像识别领域做出了重要贡献,是 CNN 手写数字识别的第一人。现任纽约大学教授,Facebook 首席科学家。以手写字体识别、图像压缩和人工智能硬件等主题发表过 190 多份论文,研发了很多关于深度学习的项目,并且拥有 14 项相关的美国专利。同自己的老师 Geoffrey Hinton 共同反向传播算法,成为神经网络训练的常用算法。
- Yoshua Bengio: 加拿大蒙特利尔大学教授,其一篇「A neural probabilistic language model」论文开创了神经网络语言模型的先河。其整体思路影响、启发了之后的很多基于神经网络做 NLP(自然语言处理)的研究,在工业界也得到了广泛使用,还有梯度消失(gradient vanishing)的细致分析,word2vec 的雏形,以及现很火的计算机翻译(machine translation)都有 Bengio 的贡献。其可生成对抗网络(GAN)的相关论文引发了计算机视觉和计算机成像领域的革命。
十二、总结
随着互联网技术的高速发展,大数据已成为了影响生产力的重要因素和行业资源,大数据时代的到来使得人工智能技术变得越来越智能化。
- 2012 年,在 ImageNet 竞赛上,深度学习模型 AlexNet 在图像识别分类上取得突破发展,远超传统计算机视觉算法,成为深度学习时代到来的重要里程碑。
- 2013 年,Durk Kingma 和 Max Welling 在 ICLR 上以文章《Auto-Encoding Variational Bayes》提出变分自编码器(Variational Auto-Encoder,VAE)。
- 2014 年,Goodfellow 及 Bengio 等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。
- 2015 年,为纪念人工智能概念提出 60 周年,深度学习三巨头 LeCun、Bengio 和 Hinton(他们于 2018 年共同获得了图灵奖)推出了深度学习的联合综述《Deep learning》。
- 2015 年,Microsoft Research 的 Kaiming He 等人提出的残差网络(ResNet)在 ImageNet 大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。
- 2015 年,马斯克等人共同创建 OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT 等。。
- 2016 年,谷歌围棋人工智能 AlphaGo 与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以 4 比 1 的总比分获胜。
- 2017 年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,是历史上首个获得公民身份的一台机器人。
- 2018 年,Google 提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布 Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。
- 2019 年, IBM 宣布推出 Q System One,它是世界上第一个专为科学和商业用途设计的集成通用近似量子计算系统。
- 2020 年,OpenAI 开发的文字生成 (text generation) 人工智能 GPT-3,它具有 1,750 亿个参数的自然语言深度学习模型,比以前的版本 GPT-2 高 100 倍,该模型经过了将近 0.5 万亿个单词的预训练,可以在多个 NLP 任务(答题、翻译、写文章)基准上达到最先进的性能。
- 2020 年,中国科学技术大学潘建伟等人成功构建 76 个光子的量子计算原型机“九章”,求解数学算法“高斯玻色取样”只需 200 秒,而目前世界最快的超级计算机要用 6 亿年。
- 2021 年,OpenAI 提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
- 2022 年,ChatGPT 出来,AI 的想象瞬时就开始爆了...未来已来
经过几十年的沉淀和发展,特别是近年来得益于数据、算力以及算法的重要突破,人工智能技术在学术界和工业界取得了广泛成功,并掀起新一轮的人工智能热潮。国内外越来越多的专家学者致力于将人工智能和深度学习模型引入各行各业中。从安防中的人脸识别到出行中的无人驾驶,从国际会议中的实时翻译到智能家居中的语音识别,无不有人工智能技术的身影。人工智能也因此成为新时代产业数字化和科技革命的核心竞争力,成为全球经济环境变化中的新动力。
以机器学习和知识图谱为代表的人工智能技术火热兴起,使得从海量非结构化数据中提取、获得医学知识成为可能,医疗系统的数字化与信息化是国内外医学发展的必然趋势。
随着移动互联网、大数据、云计算等多领域技术与医疗领域跨界融合,新兴技术与新服务模式快速渗透到医疗各个环节,并使人们的就医方式产生重大变化,也为智能医疗行业带来了新的发展机遇。